Transcription Features
99 different languages supported
UserBit's transcription module supports a host of languages with advanced models for few. You can find the list of supported languages here.
Speaker recognition
The transcription model currently supports speaker recognition for all supported languages.
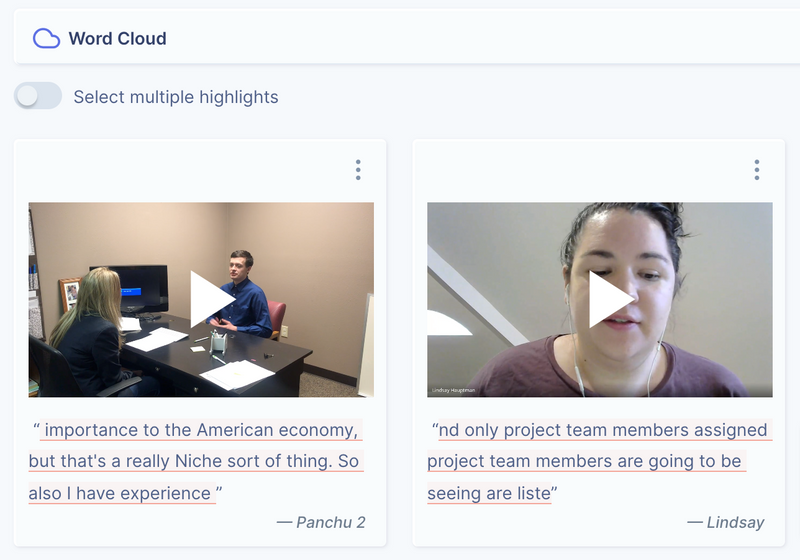
UserBit splits the transcription into separate spakers:

Pro tip: You can click on the speaker to assign a participant or stakeholder to them. This way, any highlights created within the speaker's text, will automatically be attributed to the attached participant/stakeholder.
The play button next to the speaker name, will play exactly the part of the video that corresponds to section of the transcript.

Synced video and transcript for easy analysis
As you scroll down the transcript, a companion video player scrolls with you to help you with your analysis. When you click on the video seek bar to move to a certain part of the video, the transcript scrolls to the place as well.

Similary, when you click on a speaker's section, the video also seeks to the relevant position. Moreover, you can also see exactly what in the video is being said by the highlighted words in the transcript.
Editing transcript
UserBit offers a host of features to let you edit/improve your generated transcripts — from inline editing to switching speakers. You can learn about them here.
Highlight clips
Adding a tag to a part of the transcript automatically creates a video clip spanning the length of what is being spoken in the highlighted portion. The clip is stored with the highlight and can be used in reports or insights.